摘要:目录摘要ABSTRACT深度学习新的优化器Optimization的方法:1.SGD2.SGDM3.Adagrad4.RMSProp5.Adam?Adam?vsSGDMCombineAdamwith?SGDMImprovingAdamAMSGrad:AdaBound:ImprovingSGDMCyclicalLR:SGDR:On
目录
本文介绍了优化方法中的几种常见算法,包括SGD、SGDM、Adagrad、RMSProp和Adam。这些算法在训练神经网络模型时起到关键作用。文章还介绍了一些改进的算法,如RAdam、AMSGrad、AdaBound和Lookahead,它们在提高优化算法性能和稳定性方面具有重要作用。此外,文章还提到了一些优化技巧,如学习率调度策略(如Cyclical LR和One-cycle LR)、参数更新技巧(如NAG和Nadam)以及正则化和防止过拟合的技术(如Dropout和Gradient noise)。最后,文章还介绍了一些训练策略,如数据洗牌、预热、课程学习和微调,它们对于提高模型的训练效果和性能至关重要。
This article introduces several common optimization algorithms in training neural network models, including SGD, SGDM, Adagrad, RMSProp, and Adam. These algorithms play a crucial role in optimizing the training process. The article also discusses some improved algorithms such as RAdam, AMSGrad, AdaBound, and Lookahead, which are important for enhancing the performance and stability of optimization algorithms. Additionally, the article mentions some optimization techniques such as learning rate scheduling strategies (e.g., Cyclical LR and One-cycle LR), parameter update techniques (e.g., NAG and Nadam), as well as regularization and techniques to prevent overfitting (e.g., Dropout and Gradient noise). Furthermore, the article introduces some training strategies including data shuffling, warm-up, curriculum learning, and fine-tuning, which are essential for improving the training effectiveness and performance of the models.
Optimization的方法:
1.SGD
SGD(Stochastic Gradient Descent,随机梯度下降)是一种迭代算法,每次迭代通过计算样本的梯度来更新模型参数。SGD算法是从样本中随机抽出一组,训练后按梯度的负方向更新一次,然后再抽取一组,再按梯度的负方向更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型了。这个过程会不断重复,直到达到预定的停止条件,比如达到最大迭代次数或损失函数收敛。

2.SGDM
SGDM(Stochastic Gradient Descent with Momentum)用于训练神经网络模型。它是梯度下降算法的一种改进版本,通过引入动量的概念来加速模型的收敛速度。
在传统的梯度下降算法中,每次更新模型参数时,都会根据当前的梯度方向和学习率进行参数的调整。然而,这种方法容易受到局部极小值的影响,导致模型陷入局部最优解(遇到 local minima 的问题)。
SGDM通过引入动量的概念来解决这个问题。动量可以看作是模型在参数空间中的速度,它是过去梯度方向的加权平均。在每次参数更新时,动量会考虑当前梯度和过去梯度的贡献,使得参数更新的方向更加稳定。这样可以帮助模型跳出局部最优解,更快地收敛到全局最优解。
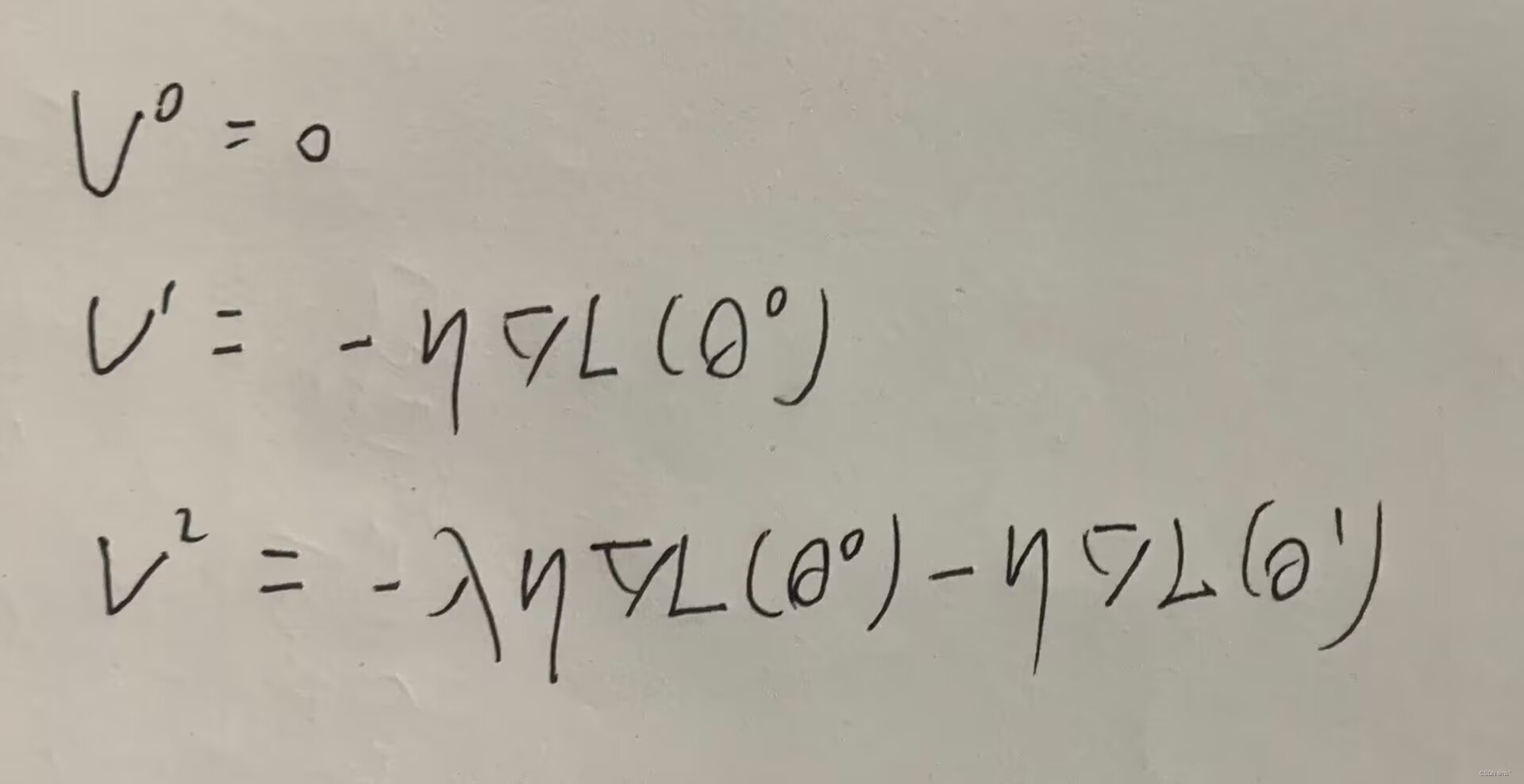

用画图的方法表示:
红色箭头表示gradient的方向,绿色箭头表示动量的方向,蓝色箭头表示真正移动的方向。前面两个位置往前移动,在第三个位置的时候的gradient的值为0,如果是SGD的方法的话就会卡在这里,因为加入了前面两个的动量,所以还会继续往下移动。在第四个位置的时候,计算的gradient的反向为反方向,如图可以明显观察到在右边会有更低的loss值,如果用SGD的话就会往回走然后卡在local minima的位置,因为前面有累加的动量momentum,所以它会继续往前走,达到更低的位置。
3.Adagrad
Adagrad(Adaptive Gradient)是一种机器学习中的优化算法,用于训练模型的参数。它是一种自适应学习率算法,旨在解决传统梯度下降算法中学习率难以设置的问题。
在传统的梯度下降算法中,学习率是一个固定的超参数,需要手动调整。然而,不同的特征可能具有不同的梯度更新需求,一些特征可能需要较大的学习率,而另一些特征可能需要较小的学习率。这就导致了一个问题,即如何选择一个合适的学习率来平衡不同特征之间的更新速度。
Adagrad是在SGD的学习效率加上了一个分母(过去所有gradient的和)。如果gradient在前几个值很大的时候,可能会走到一个更差的位置,加上了分母之后,如果过去的gradient很大的话,learning rate就小,移动的位置就小;如果过去的gradient很小的话,learning rate就大,移动的位置就大。
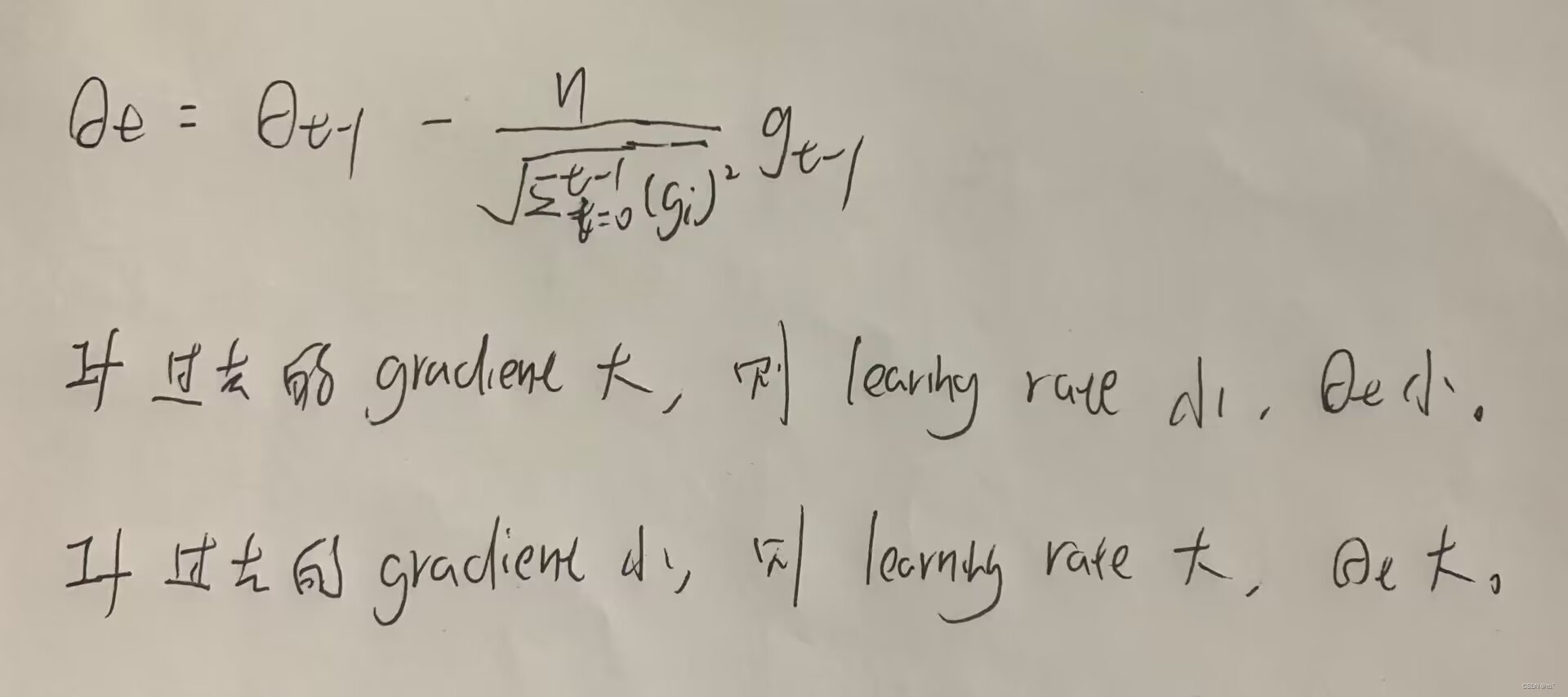
4.RMSProp
RMSProp是机器学习中的一种优化方法,它的全称是Root?Mean?Square?Propagation,即均方根传播。该算法基于梯度下降法进行优化,但与传统的梯度下降法不同,它使用了一个递归的平滑因子,对梯度进行衰减处理。
具体来说,RMSProp会计算梯度平方的移动平均数,并使用这个平均数来标准化每次迭代时的学习率。这样做的好处是可以使训练过程更稳定,避免出现梯度爆炸或消失问题。
RMSProp和Adagrad唯一的差别是在分母的算法不一样,Adagrad是将过去所有的gradient全部加起来,?RMSProp借用了类似momentum的算法,将过去的gradient的平方乘以一个α ,再将目前的gradient的平方乘以(1-α)。因为在Adagrad中,如果一开始的gradient很大,那么learning rate会很小,导致卡在某个位置,所以?RMSProp有效避免了这个问题。
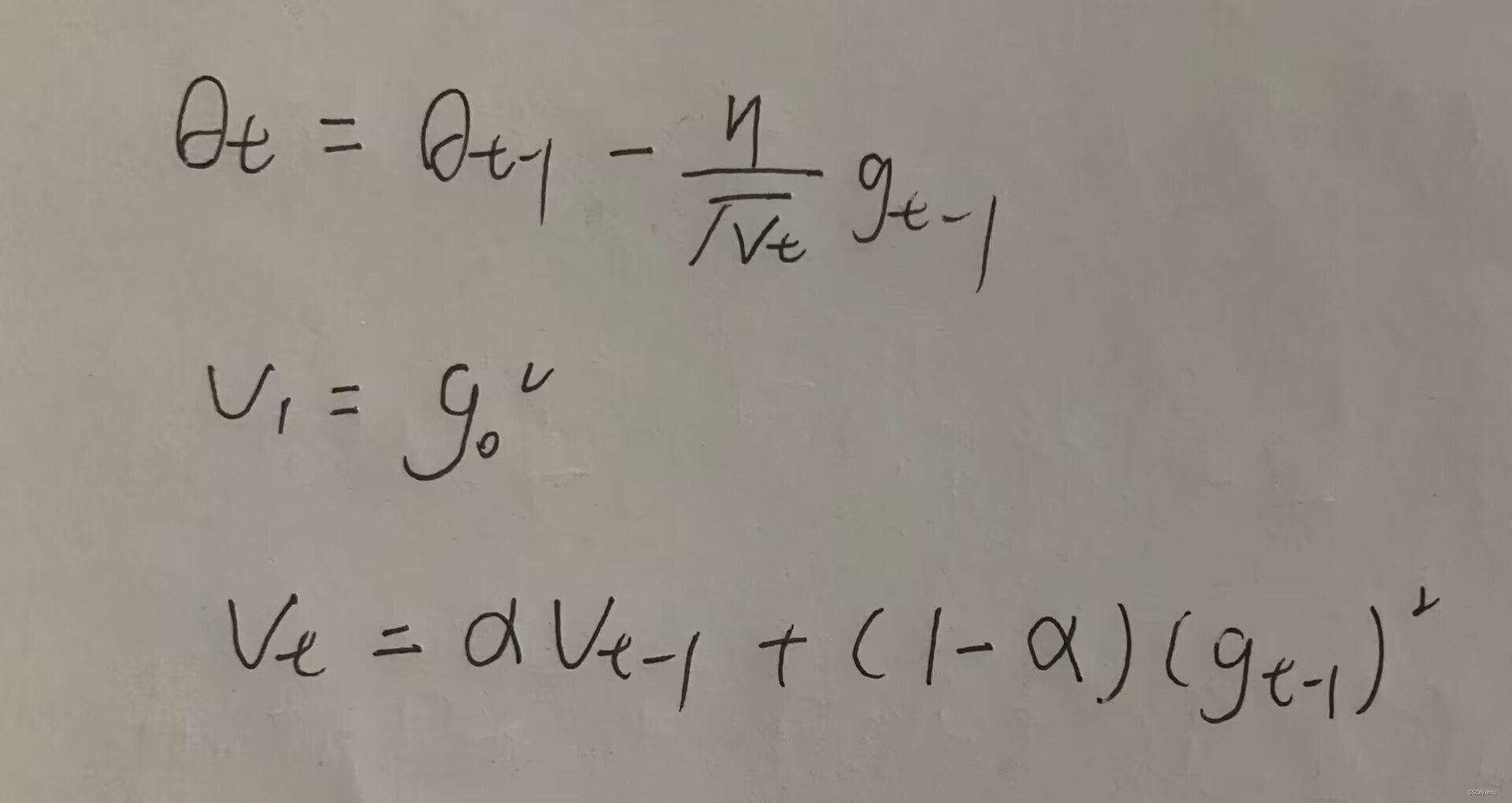
5.Adam
RMSProp仍然存在有卡在gradient为0的位置的问题。Adam(Adaptive?Moment?Estimation)结合了Momentum和RMSProp两种优化算法的优点,同时能够自适应地调整学习率,能够有效解决这个问题。
Adam算法的核心思想是计算每个参数的自适应学习率。它根据每个参数的梯度和历史梯度的平均值来动态地调整每个参数的学习率。
具体来说,Adam算法在每次迭代中计算三个指数加权平均数,分别是当前梯度、上一次梯度的指数加权平均数和上一次梯度平方的指数加权平均数。通过这三个指数加权平均数来更新参数。

?Adam? vs SGDM
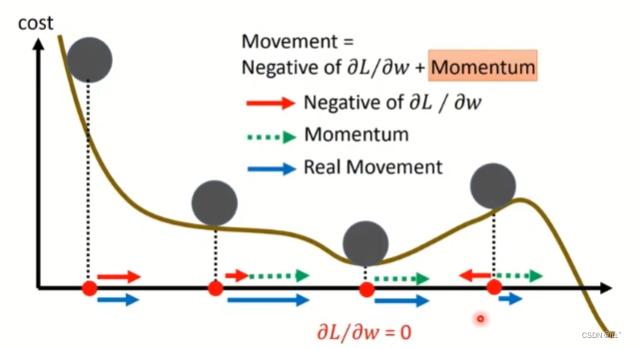
Adam相对于SGDM具有更快的收敛速度、更好的性能表现和更大的鲁棒性,并且不需要设置复杂的超参数即可自适应调整学习率大小。Adam通常训练的时候比较快,SGDM比较稳定。
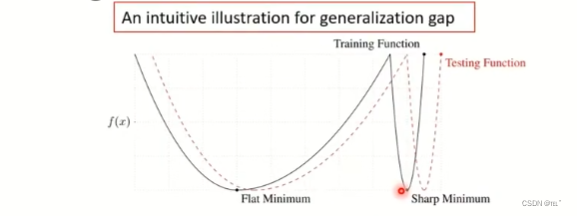
Adam在训练时大部分的时候很好,但是在generalization的能力上有比较大的落差。相对来说SGDM落差比较小。如图两个loss function,在平坦的地方的generalization就不会相差太大,但是在陡峭的地方的话,generalization的差距就非常大。
CombineAdam with?SGDM
Adam具有更快的收敛速度,SGDM比较稳定,并且在训练最后阶段能够收敛到比较小的值。那么结合Adam和SGDM会得到更好的效果。
SWATS:一开始使用Adam,后来在收敛阶段使用SGDM。

RAdam:一开始使用SGDM,后来ρ(t)大于4的时候使用RAdam。
RAdam是一种改进的优化算法,通过修正学习率和梯度估计的偏差问题,提高了模型训练的性能。它是在Adam算法基础上的一种改进,可用于提高模型的稳定性和收敛速度。
定一个ρ(t)、ρ无限大来估计r(t),当var越大的时候,走小步点;当var越小的时候,走大步点;

Improving Adam
如何让Adam像SGDM一样收敛的又稳又好?
AMSGrad:
AMSGrad是一种机器学习中的优化算法,用于训练神经网络模型,是Adam算法的一种改进版本,AMSGrad保留了Adam算法中计算历史梯度平方的指数移动平均,但在计算学习率时,移除比较小的gradient造成的影响,V(t)取较大的一个,避免被小的gradient影响。这样可以避免学习率的过度衰减,提高模型的收敛性和稳定性。
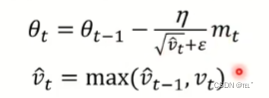
AdaBound:
AdaBound是一种机器学习中的优化算法,旨在解决Adam算法中学习率衰减过快的问题。Adam算法在训练过程中学习率可能会过快地衰减,导致模型无法充分收敛。
AdaBound算法通过引入上界和下界来限制学习率的变化范围,把learning rate做一次Clip,从而解决Adam算法中学习率衰减过快的问题。具体而言,AdaBound通过在Adam算法的学习率更新公式中添加了一个参数来限制学习率的变化速度。当学习率接近上界或下界时,它会逐渐减小学习率的更新量,以避免过快的衰减。

Improving SGDM
如何让SGDM像Adam一样快?
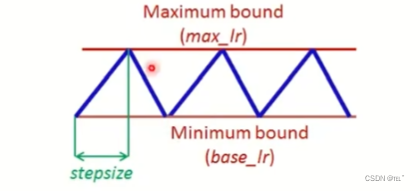
Cyclical LR:
Cyclical Learning Rate (CLR) 是一种机器学习中的学习率调度策略,采用了一种周期性变化学习率的策略。传统的学习率调度方法,如固定学习率或衰减学习率,通常需要手动调整学习率的值或衰减率。这可能会导致学习率设置不合理,从而影响模型的收敛性和性能。
CLR通过在训练过程中周期性地改变学习率的值,以一定的范围内进行波动,从而提高模型的训练效果。帮助模型跳出局部最优解,提高模型的收敛性和性能。
SGDR:
SGDR是一种基于随机梯度下降SGD的改进算法。SGD可能会陷入局部最优解或者在训练过程中收敛速度较慢的问题。SGDR通过引入周期性的学习率重启来改进SGD算法。这种周期性的学习率重启可以帮助模型跳出局部最优解,更好地探索参数空间。

One - cycle LR:
One-cycle learning rate (LR) 通过在训练过程中将学习率从一个较小的值逐渐增加到一个较大的值,然后再逐渐减小回去,形成一个完整的学习率循环。
One-cycle LR 的目标是在尽可能短的时间内训练出高性能的模型。它通过在训练过程中调整学习率的变化范围,帮助模型更快地收敛,并且降低过拟合的风险。
One-cycle LR 通常分为三个阶段:上升阶段、下降阶段和衰减阶段。在上升阶段,学习率从一个较小的值逐渐增加到一个较大的值,这有助于模型快速收敛。在下降阶段,学习率逐渐减小,帮助模型进一步优化和稳定。在衰减阶段,学习率继续减小,以防止模型过拟合。

Adam need warm-up
-
避免初始阶段的不稳定性:在训练初期,模型的参数可能处于一个相对不稳定的状态,此时使用较大的学习率可能导致训练不稳定,甚至无法收敛。通过warm-up,可以使用较小的学习率来稳定训练,帮助模型在初始阶段更好地适应数据。
-
提高泛化能力:较小的学习率可以使模型更加关注数据中的细节和特征,从而提高模型的泛化能力。通过warm-up,模型可以在初始阶段更好地捕捉数据的结构和模式,为后续的训练提供更好的基础。
-
防止过拟合:使用较小的学习率可以减少模型在初始阶段对训练数据的过拟合风险。通过warm-up,模型可以在初始阶段更加谨慎地调整参数,避免过度拟合训练数据。
Lookahead
Lookahead可以与其他内部优化算法(如随机梯度下降)结合使用,以提高模型的训练效果。
Lookahead的参数更新过程可以分为两个阶段:慢速更新(slow update)和快速更新(fast update)。慢速更新是指Lookahead优化器通过平滑参数轨迹来更新自身的参数,而快速更新是指内部优化器根据慢速更新的参数来更新模型的实际参数。如下图θ表示快速更新,Φ表示慢速更新。
通过引入Lookahead,可以实现更稳定和更快速的参数更新。它可以帮助模型跳出局部最优解,更好地探索参数空间,并提高模型的泛化能力。此外,Lookahead还具有自适应性,可以根据训练过程中的具体情况动态调整参数更新策略。

NAG:
NAG(Nesterov Accelerated Gradient)是一种基于梯度的优化方法,通过引入动量来加速梯度下降过程。在传统的梯度下降算法中,参数更新是根据当前位置的梯度来进行的。
NAG的核心思想是在梯度下降过程中,利用动量来提前预测下一个位置的梯度,从而更加准确地更新参数。这样做的好处是可以减小在陡峭斜坡上的震荡,加速收敛速度,并且在曲线的平坦区域能够更好地探索参数空间。
具体而言,NAG的参数更新过程可以分为两个阶段:预更新(pre-update)和最终更新(final update)。预更新阶段根据当前位置的动量来计算预估的下一个位置,然后在最终更新阶段根据这个估计位置的梯度来进行参数的最终更新。

Nadam:
把NAG用在adam上面。
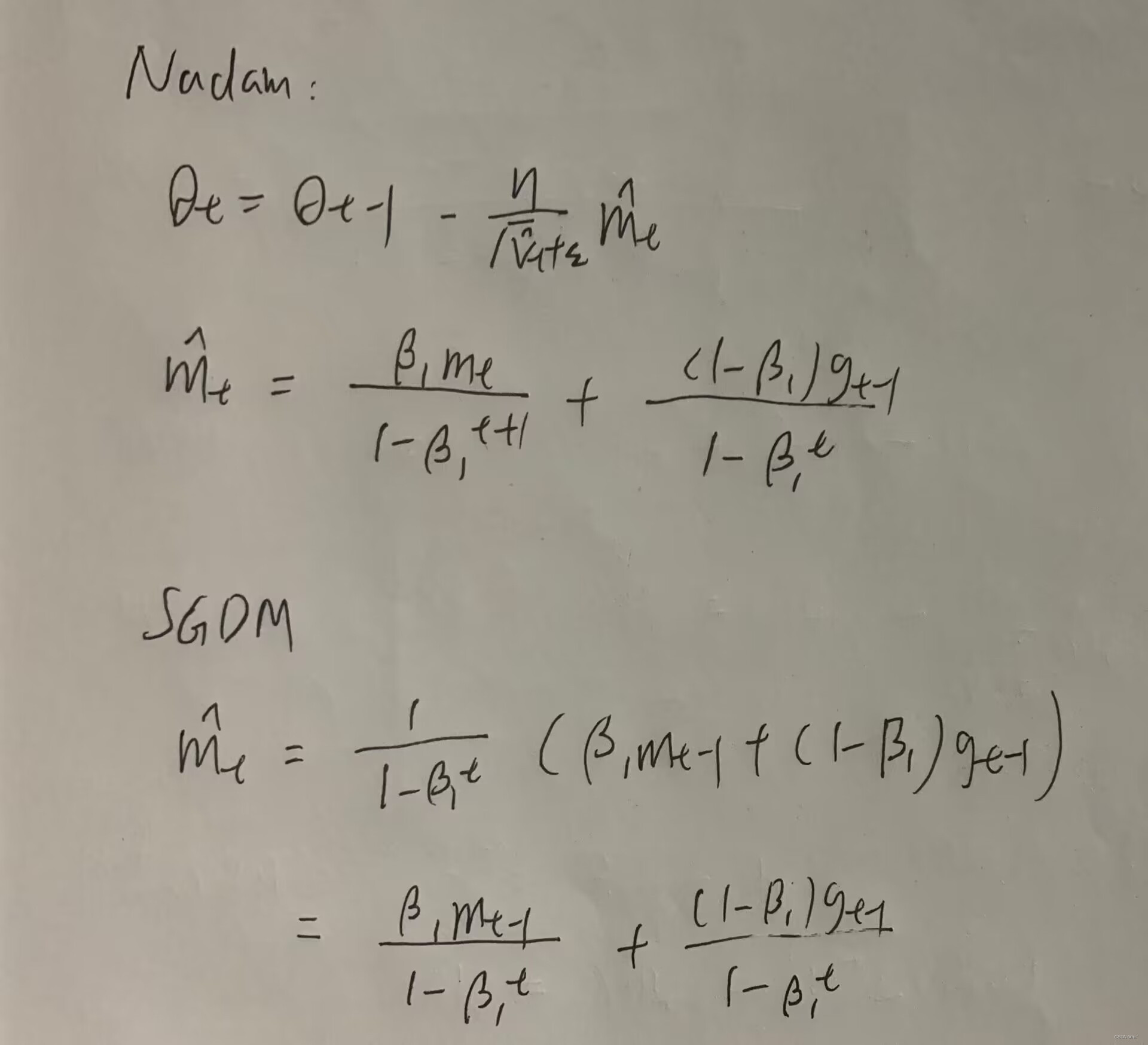
可以帮助optimization的方法:
Shuffling:
Shuffling(洗牌)是指对数据集中的样本进行随机重排的操作。这个操作通常在训练模型之前进行,旨在打乱样本的顺序,以避免模型对数据的顺序依赖性。
Dropout:
Dropout是一种用于正则化和防止过拟合的技术,在训练过程中随机丢弃一部分神经元,减少神经元之间的相互依赖性,提高模型的鲁棒性和泛化能力。
Gradient noise:?
Gradient Noise是一种在优化算法中引入随机噪声的技术,用于增加梯度的多样性和稳定性,改善模型的训练过程和泛化能力。
?Warm - up:
Warm-up(预热)是一种在训练开始阶段使用较小学习率,并逐渐递增学习率的策略。它可以帮助模型更好地初始化和调整参数,提高模型的收敛性和性能。
Curriculum learning;
Curriculum Learning(课程学习)是一种按照难度逐步增加的训练策略,通过引入简单到复杂的样本或任务,帮助模型逐渐学习和提高泛化能力。
Fine - tuning:
Fine-tuning(微调)是一种在预训练模型的基础上进一步调整模型以适应特定任务或领域的训练策略。它利用预训练模型的通用特征和知识,加速新任务的学习过程,并可以避免从头开始训练的大量资源和时间消耗。
优化方法是在训练神经网络模型时非常重要的一部分。常见的优化算法包括SGD、SGDM、Adagrad、RMSProp和Adam。这些算法通过不同的方式来更新模型参数,以使模型逐渐收敛到最优解。此外,还有一些改进的算法,如RAdam、AMSGrad、AdaBound和Lookahead,它们在提高优化算法的性能和稳定性方面发挥了重要作用。
除了优化算法,还有一些优化技巧可以帮助提高模型的训练效果。学习率调度策略(如Cyclical LR和One-cycle LR)可以在训练过程中动态地调整学习率,以提高模型的收敛性和性能。参数更新技巧(如NAG和Nadam)可以通过引入动量来加速梯度下降过程。正则化和防止过拟合的技术(如Dropout和Gradient noise)可以帮助提高模型的泛化能力和稳定性。
此外,还有一些训练策略可以进一步改善模型的训练效果。数据洗牌可以打破数据的顺序性,使模型更好地学习数据的分布。预热可以在训练开始阶段使用较小的学习率,有助于模型更快地收敛。课程学习可以按照难度逐步增加的方式来训练模型。微调可以在预训练模型的基础上进一步调整模型以适应特定任务或领域。
了解和应用不同的优化方法、技巧和训练策略对于提高神经网络模型的训练效果和性能至关重要。