摘要:深度学习常用优化器学习总结常用优化器SGDRMSPropAdam基本思想:通过当前梯度和历史梯度共同调节梯度的方向和大小我们首先根据pytorch官方文档上的这个流程来看吧(1)最基础的梯度反向传播过程我们先把其他的部分用马赛克去掉,恢复到最
基本思想:通过当前梯度和历史梯度共同调节梯度的方向和大小
我们首先根据pytorch官方文档上的这个流程来看吧
(1)最基础的梯度反向传播过程
我们先把其他的部分用马赛克去掉,恢复到最基础的梯度反向传播过程,其实就是下图这两三个流程。

符号具体作用不用太在意,相信详细学习过神经网络的同学都可以理解。最下面的梯度方向传播其实就是将 t-1 时刻的参数θ(t-1)减去 梯度变化γgt ,就能得到 t 时刻更新的参数θ(t),而减去梯度的大小,就有学习率 γ 来调节。
SGD就是在这个基础上添加一些参数来实现一些功能。
(2)momentum(动量)和dampening(阻尼)

图片中有三个红框,最上面的红框是添加的参数动量μ和阻尼参数T,而最下面的红框则是将bt传给gt。我们具体看看中间的红框(里面有两个蓝框的那个红框)。
首先解释一下,动量就是动的力量,动量参数越大,新更新的得到参数也就受上一次参数大小的影响越大;阻尼就是阻挡变化嘛,阻尼参数越大,梯度对参数的影响就越小嘛。
- 中间的红框我们可以看到首先有一个条件判断μ≠0,其实就是动量参数,当动量参数μ=0时,我们也就没必要进行这部分的计算了。
- 接下来又是一个条件判断t>1,t是表示反向传播的次数,这个是判断当前的反向传播是否是第一次。当t<=1时,其实就是第一次反向传播,由于动量需要之前反向传播的梯度计算得到(看左边的蓝框所示μ*b(t-1)),所以第一次反向传播时计算不了动量,没有动量,也就不需要计算阻尼去控制动量的大小。所以我们只有在t>1时,也就是第二次梯度反向传播时,才能在梯度中嵌入动量和阻尼。
- 我们看看动量和阻尼的核心计算部分。

我们把核心计算部分分成动量部分和阻尼部分。
①动量部分
在动量部分的计算是由动量参数×上次的动量bt-1得到,结合动量词义,其实就是我们的梯度每次都是根据样本计算而来的,但是每批次训练的样本有一定的随机性,所以我们梯度的方向并不是准确的最优的方向,但是结合每次的梯度会有一个大体的下降方向。因此有动量的话,就可以往正确的方向收敛得更快。,如下图。
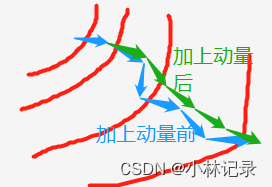
②阻尼部分
阻尼部分的作用就是控制当前梯度gt需要保留多少。显然,阻尼参数τ越大,当前新的梯度保留得越少,生成的 b 就受动量的影响越大。
SGD pytorch官网完整流程

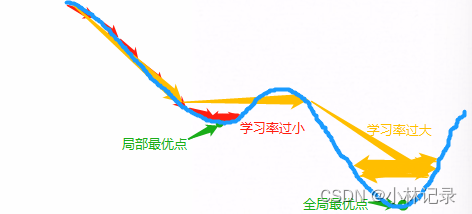
由于在模型训练过程中,同一个学习率并不能很好地适应各个训练阶段的模型,如果刚好的设置了一个较大的学习率,前期训练收敛速度快,但是后期不能让模型损失到达最优点,而让损失在局部最优点反复横跳,导致准确率震荡;而如果前期设置的学习率较小,则会导致前期收敛速度慢,难以跳出局部最优点,如下图。而手动调节各个训练阶段的SGD学习率大小又非常麻烦。
RMSProp基本思想:通过动态调节学习率去优化梯度的方向和大小,也就是让学习率自主地放大缩小,来让模型更好地拟合。
同样我们看pytorch官网上的公式,先看RMSProp的基本流程,用马赛克去掉细节的部分。

红框的核心计算公式可以表示如下。其实就是让梯度很大的时候,让学习率变小;梯度很小的时候,让学习率变大。其实我们看下图的核心计算公式,显然,如果减号右边的分母为1的话,它就是一个SGD的基本计算流程。
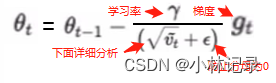
详细分析那个vt
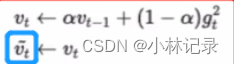
这一部分有点像SGD结合了动量和阻尼的计算公式,动量和阻尼,是根据梯度直接让梯度的方向和大小往正确的方向去拟合,而RMSProp这部分是根据当前梯度,让学习率往更好地方向去变化(梯度大,则让学习率变小;梯度小,则让学习率变大),其中梯度gt要加平方是为了让它能保证是大于0,后面又有个根号变回来。
这样就能让一些梯度较小的模型更快地收敛,梯度较大模型的收敛速度逐渐放慢。
RMSProp pytorch官网完整流程

Adam的基本思想是结合了SGD的momentum和RMSProp的根据梯度大小的学习率自主改变。
同样先看pytorch官网的Adam计算流程,并用马赛克去掉冗余部分,看主要部分。其中,β1的默认值是0.9,β2的默认值0.999(后面有用)。

我们将框1和框2合并起来,通过一系列的转换,可以得到下式
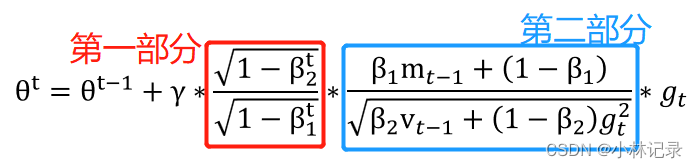
①第一部分
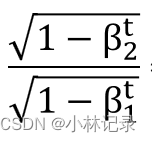
首先我们来看第一部分,它与时间相关,这里的 t 是反向传播的次数。
我们上面提到 β1的默认值是0.9,β2的默认值0.999,也就是说当t=1时,把默认值代入,我们会发现第一部分是一个比较小的数值(≈0);而随着训练的进行,t 值会越来越大,也就是最终 t = ∞,这个时候带入,会发现第一部分 = 1,那么第一部分就是一个随着训练的进行,数值会从0~1变化的函数。也就是让学习率在训练刚开始时较小,无限趋近于0;随着训练的增加越来越大,直到无限趋近于 1。
②第二部分
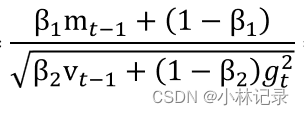
首先我们看分子,分子其实就是SGD中的momentum机制,m就是moment(动量)的缩写,mt就是表示t时刻的动量,让我们可以在训练过程中让损失在对的方向下降得更快。可以参考上述SGD部分。
其次我们看分母,它其实就是RMSProp中的根据当前梯度自主调节学习率,当梯度越大,则分母越大,那么整个分数就变小,即可以让整体梯度变小;当梯度越小,则分母越小,那么整个分数就变大,即可以让整体梯度变大。
注意:Adam的 t 非常重要,由于有时候模型训练会中断再继续训练,这个时候我们就需要保持 t 的状态。 可以参考第一部分的计算,会影响Adam优化器的效果。
Adam pytorch官方完整流程

以上。欢迎交流,如有错误,请各位大佬指正,非常感谢!!!