摘要:深度学习作为一个非凸优化,对优化器的选择比较敏感,本文梳理一下常见的深度学习优化器。另外,考虑到二阶优化器的计算量太大,在深度学习中并不常见,就仅仅讨论了一阶优化器。最简单的优化器,沿着负梯度的方向更新参数。现在的SGD大部分情况下指的是mini_batchSGD,梯度的计算平均了批次中的所有样本:
深度学习作为一个非凸优化,对优化器的选择比较敏感,本文梳理一下常见的深度学习优化器。另外,考虑到二阶优化器的计算量太大,在深度学习中并不常见,就仅仅讨论了一阶优化器。
最简单的优化器,沿着负梯度的方向更新参数。现在的SGD大部分情况下指的是 mini_batch SGD,梯度的计算平均了批次中的所有样本:
x +=-learning_rate * dx如果计算所有样本的梯度,并且学习率很小的情况下,可以保证 loss 单调递减。
缺点:容易困在局部最小值 。
在 naive SGD 上引入了动量,参数的更新会参考之前下降的方向,可以使参数突破 local minima ,通常来说会更快收敛。
v记录了历史所有的梯度更新,初始值为0,超参数 就是动量, 可以理解为摩擦力系数。
关于 的设置,可以从一个较小值开始,比如 0.5, 然后逐渐增大至 0.99 。
关于动量的物理意义可以参考其他资料。
不同于标准的动量方法,NM 收敛更快,效果更好。
可以看出 NM 计算的梯度方向是在计算了动量之后的梯度,因为参数是一定会走到这个地方的,这个做法叫做 look-ahead。
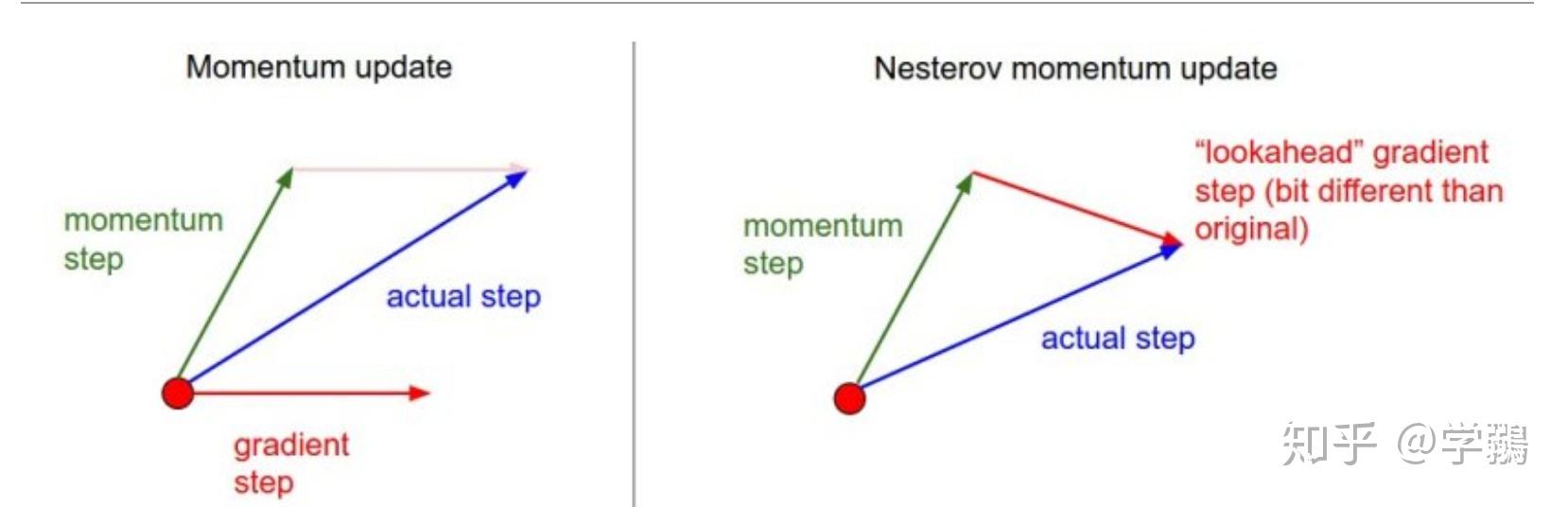
在实际的操作中,会采用下面的做法:
v_prev=v
v=mu * v - learning_rate * dx
x +=-mu * v_prev + (1 + mu) * v 这个方法是和上面的形式不同,结果是一样的。
前面的方法都是设置了全局学习率,对每一次迭代、每一个参数都是一样的,adagrad 是一个自适应学习率的优化器。
cache +=dx**2
x +=- learning_rate * dx / (np.sqrt(cache) + eps)cache 存储区了所有的梯度的平方,是单调递增的函数,起到调节学习率的作用,使学习率单调递减。
要注意的是 cache 是一个向量,这样 x 的每一个维度的学习率都是不同的!
eps 通常设置为一个很小的数,防止除零。
改进了Adagrad,使得 cache 不再单调递增,而是历史梯度评分的滑动平均。
cache=decay_rate * cache + (1 - decay_rate) * dx**2
x +=- learning_rate * dx / (np.sqrt(cache) + eps)decay_rate 是一个超参数,通常设置为0.9。
adam就很像是 RMSprop 加上动量。
简化的形式如下:
m=beta1*m + (1-beta1)*dx
v=beta2*v + (1-beta2)*(dx**2)
x +=- learning_rate * m / (np.sqrt(v) + eps)m 就是动量, v 就是cache,通常设置为0。 beta1、beta2、eps 都是超参数。
论文中是这样设置的:
eps=1e-8,beta1=0.9,beta2=0.999 在实做中,由于刚开始的迭代中,m 和v 都接近于0 , 不利于参数更新,因此对m 和 v 进行校正。如下所示,t 为跌代的次数,使得刚开始的 m 和 v 都被放大。
m=beta1*m + (1-beta1)*dx
mt=m / (1-beta1**t)
v=beta2*v + (1-beta2)*(dx**2)
vt=v / (1-beta2**t)
x +=- learning_rate * mt / (np.sqrt(vt) + eps)通常来说,模型更新到后期,太大的学习率会导致模型收敛很慢,因此要对学习率进行控制。
step decay:
若干个 epoches 之后就对学习率进行衰减,比如5个 epoch 之后减半等。一个启发式的办法是观察验证集的 loss ,饱和之后就固定值衰减等。
Exponential decay:
a 初始学习率, 都是超参数,t 是迭代的次数或者epoch数。
1/t decay:
通常来说,选择 step decay 比较好。